Oracle GoldenGate till version 11.2 could only work serially. The only way of creating parallel replication and speeding up the apply process was to create multiple Replicat processes. In version 12.1 there was a new option available: the Coordinated Replicat. It is often misunderstood as a way of speeding up transactional replication. But … is this way of replication fully ACID complaint? Let’s find out.
1. Versions
Before making any conclusions I would like to note the OGG versions that I have used for my research:
1. OGG 12.1.2.1 + patch 170117, Database 11.2.0.4 + PSU 11.2.0.4.180417 + 17030189
2. OGG 12.2.0.2.2 + patch 170630, Database 12.1.0.2 + PSU 12.1.0.2.180417
3. OGG 12.3.0.1.2 + patch 171208, Database 12.2.0.1 + RU 12.2.0.1.180417
These are the latest versions as of April 2018, the platform is Linux 64.
All tests I have performed have been run on all 3 configurations.
2. Parallel Classic Replicat
Classic Replicat did not have a way of paralleling Replicat apply processes. The only way was to … create multiple Replicat processes and dividing the load manually between the Replicat processes. This could be performed using the FILTER clause and the @RANGE function, for example like this:
Replicat #1:
TABLE bill.PERSON, FILTER (@RANGE(1, 3, CUSTOMER_ACCOUNT)); TABLE bill.PAYMENT, FILTER (@RANGE(1, 3, CUSTOMER_ACCOUNT)); TABLE bill.PAYMENT_SUMMARY;
Replicat #2:
TABLE bill.PERSON, FILTER (@RANGE(1, 3, CUSTOMER_ACCOUNT)); TABLE bill.PAYMENT, FILTER (@RANGE(1, 3, CUSTOMER_ACCOUNT));
Replicat #3:
TABLE bill.PERSON, FILTER (@RANGE(3, 3, CUSTOMER_ACCOUNT)); TABLE bill.PAYMENT, FILTER (@RANGE(3, 3, CUSTOMER_ACCOUNT));
In this example the PAYMENT_SUMMARY has no CUSTOMER_ACCOUNT column, so it can not be assigned to any of the 3 Replicats. All rows of this table are fully processed by Replicat #1.
This way of dividing replication into 3 parallel threads allows to achieve the increase in the speed very fast. It is a scalable solution – you can increase the number of processes to achieve higher throughput.
The drawback is … that this way is completely not ACID compliant. For example, Replicat #2 replicates only a part of transactions and it is only interested in a part of 2 tables. A transaction that involves DML operations of the bill.PAYMENT_SUMMARY and bill.PAYMENT tables could be divided in 2 or 3 transactions.
The Replicat processes operate independently and are not synchronized. One of them could be completely ahead and other far behind. As a result some queries run on the target site could give results that could be never achieved on the source site.
If you are using this approach you have to deeply understand your application and agree on the drawbacks that the queries on the target site could give strange results.
3. Coordinated Replicat
The same approach as above could be achieved using Coordinated Replicat with the following param file:
TABLE bill.PERSON, THREADRANGE(1-3, CUSTOMER_ACCOUNT); TABLE bill.PAYMENT, THREADRANGE(1-3, CUSTOMER_ACCOUNT); TABLE bill.PAYMENT_SUMMARY;
This configuration is much easier to manage and gives exactly the same results. You have just one Replicat process and you can additionally put synchronization points using COORDINATED clause with the TABLE/MAP or SQLEXEC clauses.
4. Test cases
Let’s now look at some test cases to fully understand the consequences of this approach.
4.1. Mixing THREAD and NO THREAD
In the first scenario when we have a transaction which involves one table that uses the THREAD/THREADRANGE and one table that does not use it. The table that does not use the thread parameter is just always replicated using the first thread. The parameters in the Replicat processes is like shown in p. 3 above.
The transaction is:
INSERT INTO bill.PERSON(CUSTOMER_ACCOUNT) values (1); INSERT INTO bill.PAYMENT_SUMMARY(SUMMARY) values (100); COMMIT;
There are actually 2 possible scenarios. One that this transaction is replicated as a whole (like on the source), and the second – that it is divided into 2 transactions on the replicate:
INSERT INTO bill.PERSON(CUSTOMER_ACCOUNT) values (1); COMMIT;
The second thread would apply the transaction:
INSERT INTO bill.PAYMENT_SUMMARY(SUMMARY) values (100); COMMIT;
4.2. THREAD with multiple rows in one table
The scenario is to replicate a transaction that involves 2 rows of the same tables but which are using different primary keys.
The transaction is:
INSERT INTO bill.PERSON(CUSTOMER_ACCOUNT) values (1); INSERT INTO bill.PERSON(CUSTOMER_ACCOUNT) values (2); COMMIT;
Actually since the CUSTOMER_ACCOUNT column is used as a key almost certainly the INSERT operations will be divided into 2 transactions executed by 2 threads:
INSERT INTO bill.PERSON(CUSTOMER_ACCOUNT) values (1); COMMIT;
And:
INSERT INTO bill.PERSON(CUSTOMER_ACCOUNT) values (2); COMMIT;
4.3. Two tables using THREAD and same column as key
The next scenario checks the ability to group DML operations based on the column CUSTOMER_ACCOUNT.
The source transaction is:
INSERT INTO bill.PERSON(CUSTOMER_ACCOUNT) values (1); INSERT INTO bill.PERSON(CUSTOMER_ACCOUNT) values (2); INSERT INTO bill.PAYMENT(CUSTOMER_ACCOUNT) values (1); INSERT INTO bill.PAYMENT(CUSTOMER_ACCOUNT) values (2); COMMIT;
Since the CUSTOMER_ACCOUNT is used for grouping this would be replicated by one thread as:
INSERT INTO bill.PERSON(CUSTOMER_ACCOUNT) values (1); INSERT INTO bill.PAYMENT(CUSTOMER_ACCOUNT) values (1); COMMIT;
And a second one as:
INSERT INTO bill.PERSON(CUSTOMER_ACCOUNT) values (2); INSERT INTO bill.PAYMENT(CUSTOMER_ACCOUNT) values (2); COMMIT;
This seems very logical.
4.4. Foreign key constraints
I have checked the constraints on the source site and it seems that they have no influence on the way the transactions are divided into Coordinated Replicat threads. Constraints are completely ignored and if they appear on the target site, this can cause the Replicat process to abend if the order of transactions has been changed.
Using this type of replication requires to remove all foreign key and unique constraints from the target database as this could cause problems for the replication.
It seems that there is a deterministic static hashing function used to divide the DML operations between threads and it ignores the existence of constraints on the source database.
5. Coordinated parameter
Coordinated Replicat is way more advanced than a group of Classic Replicats because it has the ability to synchronize all threads using the COORDINATED parameter in the TABLE/MAP or SQLEXEC clause. You can not achieve the same functionality with multiple Replicat processes since all of them operate completely independent.
But either way you have to be absolutely know all types of your transactions and manually coordinate what is replicated and how they are decomposed. Overusing the COORDINATED clause diminishes the gain from parallel replication.
6. Checkpointing
One of the most important aspects is the way that OGG uses checkpointing with Coordinated Replicat.
When the Coordinated Replicat is stopped OGG makes sure that all the Replicat checkpoint of all the target threads is equal. If some threads have are behind, they must catch up the first thread. In case of abnormal shutdown of the Replicat process the checkpoints can be equalized using the SYNCHRONIZE REPLICAT command.
As I have written in my previous post about checkpoint table, the Coordinated Replicat can not work with the NODBCHECKPOINT setting. It always has to use checkpoint table for coordinating replicated data. Let’s look how it populates the checkpoint table.
6.1. Checkpoint table
Looking into the checkpoint table shows that it contains one row per every thread of the Coordinated Replicat. From the functional point of view it looks like those Threads were independent Replicat processes – every one of them has a separate queue of transactions to replicate. Rows are assigned to Replicat threads using a deterministic hashing function based on row PK’s or columns specified in the THREADS/THREADRANGE parameter.
Before applying the commit operation on the target database the Replicat threads also has to update the specific row of the checkpoint table in the target database. The update is performed in the same transaction, so that the Replicat thread can be later absolutely sure what has been applied. The UPDATE of the row updates the following columns:
- LOG_CMPLT_CSN – the CSN of the transaction that has been applied,
- LOG_CMPLT_XIDS – the transaction ID of the transaction that has been applied.
Looking at the checkpoint table you can clearly see where what has been applied and what not. Unfortunately you can not easily tell looking at the trail which DML operations are assigned to which thread.
It seems that the checkpoint table contains all crucial information about the state of the Replicat. In case target database has been recovered to an earlier state it seems that it could be possible to resync the Replicat processes (assuming that you have all the required older trail files). I assume also that meanwhile you can not change the param file. I am planning to test such scenario in the future and write some note about the results on my blog. Stay tuned.
6.2. GROUPTRANSOPS and DISABLECOMMITNOWAIT
One last note about the GROUPTRANSOPS and the DISABLECOMMITNOWAIT parameters. I am totally ignoring those parameters in this analysis, because they have no influence on the mode the DML operations are divided an how the transactions are broken into peaces. There are of course significant performance implications but I have left the default values for both of them.
7. Conclusions
To understand the Coordinated Replicat you have to treat it as an enhanced variant of multiple Replicat processes with the ability to synchronize in specific circumstances.
This image is a good explanation of how Coordinated Replicat divides the work between threads:
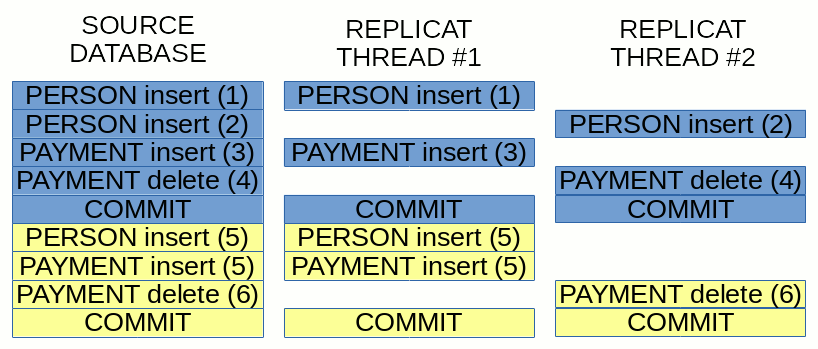
I have used a simplification, so that rows with odd ID’s are processed by Replicat Thread #1 and even ID’s are processed by Replicat Thread #2. Of course in real live the hashing function which divides the load can work in a different way. But still the image shows the idea of dividing the transactions between threads keeping the transaction boundaries.
I have noticed no differences between versions 12.1, 12.2 and 12.3. It seems that the development of Coordinated Replicat has been suspended after presenting this functionality in OGG 12.1.
I want to repeat again the warning about using this mode. You have to very deeply understand the characteristics of the transactions on the source system and agree to the fact that this type of replication does honor the transaction boundaries (transactions are cut into peaces) and some threads may be ahead of others. Meaning that sometimes if you run queries (especially aggregates) on the target you may have abnormal results which could never appear on the source system.
If the drawbacks of this solution are not a problem for the business user of the target site then this could be a very good candidate for the replication configuration.